
MachineLab
MachineLab
MachineLab
MachineLab
MachineLab
Ascendeum
Ascendeum
AI/ML infrastructure
AI/ML infrastructure
Product Design, B2B, SaaS
Product Design, B2B, SaaS
About
MachineLab is a privacy-first synthetic data + ML platform that turns sensitive production data into realistic, compliant synthetic datasets—so teams can move faster without exposing real customer data. We’re helping design the full experience, from product storytelling and workflow structure to detailed UI for a stage-based pipeline that covers data prep, training, evaluation, deployment, and monitoring. The goal is to make the whole flow feel simple, versioned, and audit-ready—so teams can safely share data, ship models quicker, and reduce re-identification risk versus traditional anonymization.
MachineLab is a privacy-first synthetic data + ML platform that helps teams share data and ship models faster with compliant, audit-ready workflows.
MachineLab is a privacy-first synthetic data + ML platform that converts sensitive production data into compliant synthetic datasets, enabling faster data sharing and model delivery through a simple, versioned, audit-ready workflow.
MachineLab is a privacy-first synthetic data + ML platform that turns sensitive production data into realistic, compliant synthetic datasets—so teams can move faster without exposing real customer data. We’re helping design the full experience, from product storytelling and workflow structure to detailed UI for a stage-based pipeline that covers data prep, training, evaluation, deployment, and monitoring. The goal is to make the whole flow feel simple, versioned, and audit-ready—so teams can safely share data, ship models quicker, and reduce re-identification risk versus traditional anonymization.
MachineLab is a privacy-first synthetic data + ML platform that converts sensitive production data into compliant synthetic datasets, enabling faster data sharing and model delivery through a simple, versioned, audit-ready workflow.
Objective
To create an intuitive, scalable ML platform that serves beginners, advanced practitioners, and administrators equally—enabling faster model deployment, reducing cognitive overload, and providing unprecedented visibility into team ML operations while maintaining the flexibility to power enterprise-grade workflows.
To build a scalable, intuitive ML platform that supports all skill levels, speeds deployment, reduces complexity, and improves operational visibility for enterprise workflows.
To create an intuitive, scalable ML platform that serves beginners, advanced practitioners, and administrators equally—enabling faster model deployment, reducing cognitive overload, and providing unprecedented visibility into team ML operations while maintaining the flexibility to power enterprise-grade workflows.
To build a scalable, intuitive ML platform for all skill levels that speeds deployment, reduces complexity, and improves operational visibility for enterprise workflows.
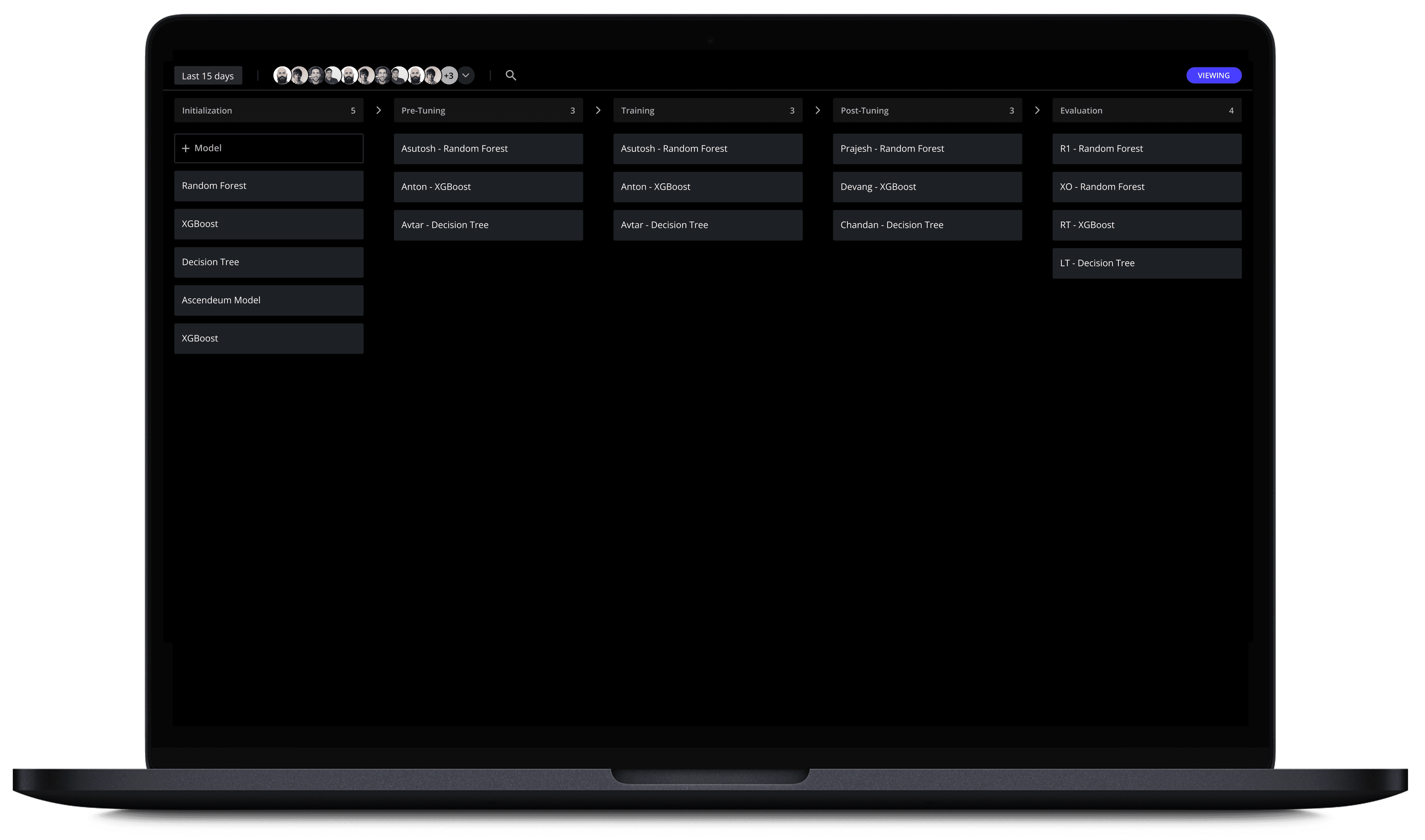

Stage Based Visual Pipeline
Each column represents a distinct ML stage, and each model becomes a card that travels through these stages.

Progressive Disclosure
When you're getting started, each card shows just the essential information. But as you click to expand, layers of complexity reveal themselves

Guided Model Discovery
Users first set the basics (learning process, objective, data format), then browse a curated model library with clear tags and “View details,” making it easy to shortlist the right approach before diving into configuration.

Contextual Editing Panel
The left rail keeps the model workflow and options always visible, while an overlay panel lets you configure the selected model (packages, parameters, secrets, tuning) without leaving the main canvas.

Checklist-Driven Pre‑Tuning
Feature engineering is broken into quick, scannable actions (missing values, encoding, dtypes, scaling), so users can configure preprocessing step-by-step, pick a target, and keep the model pipeline moving without getting lost in data prep.

Training Control Center
Before hitting run, users lock in execution settings like cloud provider and compute (CPU/GPU/TPU), with simple toggles for distributed training and auto-scaling—so performance and cost choices are clear upfront.

Pick‑Your‑Score Evaluation
Users choose the task (classification vs regression), select exactly which metrics matter, and then generate the right visual (confusion matrix, ROC, precision‑recall) to compare runs and spot tradeoffs fast.

Deployment Packaging
Users choose how to export the model (Pickle/ONNX/TensorFlow, etc.) and what to ship with it—hyperparameters, training metadata, preprocessing, and versioning—so every deployment is reproducible and ready for monitoring.

Always‑On Monitoring Controls
Teams set up drift detection and prediction logging with simple frequency and baseline dataset picks, then choose what to store (inputs, latency, ground truth comparisons) and define thresholds—so issues surface early and every run stays traceable.
hey@studiovexel.com
hey@studiovexel.com
hey@studiovexel.com
hey@studiovexel.com
HEADQUARTERED IN INDIA, SERVING CLIENTS GLOBALLY
HEADQUARTERED IN INDIA, SERVING CLIENTS GLOBALLY